Copying 20GB into PG in under 2 minutes
Recently I came across this
open dataset and I thought it would be cool to see what we could do
with it. Let’s download
2020-06-28-1593366733-fdns_cname.json.gz and extract the
contents to C:\Fun. This will give you a 20GB JSON file -
rename the file to input.json.
In my day-to-day job I work with a range of databases (PG, SQL, and Cassandra). We are slowly migrating away from SQL Server to PostgreSQL. So it makes sense to pick PG as opportunity to learn and improve my knowledge around it; in which case lets make our target to insert the above file into PG as fast as possible.
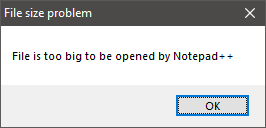
To begin with we need to know what the file looks like. I typically use Notepad++, but it can’t open a 20GB JSON file:-
A quick Google later, reveals glogg and klogg. Let’s opt to use klogg as it looks like it it is actively maintained. Impressively, klogg only takes a couple of seconds to open the file. It reveals the contents look like this:-
{"timestamp":"1593369090","name":"12301.photo.blog","type":"cname","value":"photo.blog"}
{"timestamp":"1593369141","name":"12301.udesk.cn","type":"cname","value":"6fpv23w08k2ib217.aligaofang.com"}
{"timestamp":"1593368956","name":"12301.wang","type":"cname","value":"a.mb.cn"}With a total line count of 191,245,437.
At work we typically interact with PG through Npgsql but I have a feeling that won’t work when it comes to such a massive file. Consulting the documentation for PG, we find that PG has a COPY command which states:-
COPY FROMcopies data from a file to a table (appending the data to whatever is in the table already).
Which sounds like exactly what we want.
Let’s create a table that will hold the JSON lines:-
CREATE TABLE public.tblfun
(
json_blob jsonb NOT NULL
)PG supports JSONB and JSON out of the box.
I’m opting for JSONB as guided by the documentation:-
In general, most applications should prefer to store JSON data as
JSONB, unless there are quite specialized needs, such as legacy assumptions about ordering of object keys.
To use COPY we will need to use psql.exe
which can normally be found in
C:\Program Files\PostgreSQL\<version>\bin\psql.exe.
I’m using a default installation of the of PG 9.5 (which matches the
version I use at work), and I’ll be using the default user of
postgres. I’ve added psql.exe to my path, to make my life
easier. You may want to do the same. First thing is to make sure we can
connect:-
psql.exe --username="postgres"
You should see a postgres=# prompt, typing
exit will return you back to the CLI. As it is a default
installation of PG, I’m not providing the --host,
--port, and --dbname flags as the default
values work fine.
Next step is to grab a few lines from input.json using
klogg and see if we can get a working slice. Go ahead and grab a three
or four lines and stick them in a file called
C:\Fun\input_test.json and execute:-
psql.exe --username="postgres" --command="COPY tblfun (json_blob) FROM 'C:\Fun\input_test.json';"You should see a confirmation message back from the PG CLI saying it has successfully copied in three rows:-
COPY 3
And executing:-
SELECT COUNT(1) FROM public.tblfun;Should also return three. Let’s clear out the table:-
TRUNCATE public.tblfun;This time we are going to wrap the psql.exe command in
Powershell’s Measure-Command
that will show how long it took to insert the 20GB JSON file:-
Measure-Command { psql.exe --username="postgres" --command="COPY tblfun (json_blob) FROM 'C:\Fun\input.json';"};And…failure:-
ERROR: could not stat file "C:\Fun\input.json": Unknown errorIt’s a guess but I would assume that PG isn’t happy with 20GB file being thrown at it. Let’s change tact; will it work if we reduce the input to a million lines?
Get-Content .\input.json | Select -First 1000000 | Out-File "input_test.json";
Measure-Command { psql.exe --username="postgres" --command="COPY tblfun (json_blob) FROM 'C:\Fun\input_test.json';"};And another failure!
ERROR: invalid byte sequence for encoding "UTF8": 0xffHmm, that read like it expects UTF8. Okay, no worries.
Out-File has an -Encoding flag:-
Get-Content .\input.json | Select -First 1000000 | Out-File "input_test.json" -Encoding utf8;
Measure-Command { psql.exe --username="postgres" --command="COPY tblfun (json_blob) FROM 'C:\Fun\input_test.json';"};Still a no:-
ERROR: invalid input syntax for type json
DETAIL: Token "" is invalid.You spend enough time working with text that you implicitly learn
that this is some sort of weird encoding issue. Opening
input_test.json with Notepad++ we can see the file’s
encoding is UTF8 BOM (Byte Order Marking). Unfortunately the version of
Powershell I am using does not support writing to regular UTF8,
apparently it is an option
in newer versions. Luckily we can use Notepad++ to convert it to
regular UTF8 encoding using Encoding > Convert to UTF8,
save them file and re-run:-
Measure-Command { psql.exe --username="postgres" --command="COPY tblfun (json_blob) FROM 'C:\Fun\input_test.json';"};Success! We have just inserted a million rows in ~4 seconds:-
TotalSeconds : 3.832854While we are here, how long does it take if we opt to use the
STDIN instead of FROM <file>?
Measure-Command { type input_test.json | psql.exe --username="postgres" --command="COPY tblfun (json_blob) FROM STDIN;"};Takes ~40 seconds. Yikes; I would guess because each line is processed one at a time, that the overhead of a transaction per line is causing the increase in time as well as routine vacuuming being trigged more often.
Napkin maths says that with 191,245,437 total lines and million lines per chunk would take around 191 (number of batches) * ~4 seconds which is about 13 minutes. A million rows seems like a nice batch size, so let’s see if we can split the entire file into 1 million line chunks.
Using Powershell is obviously out of the window due to its lack of regular UTF8 support. Another spin on Google spits out this very helpful answer on StackOverflow. I wasn’t raised on *nix, I’m a Windows lad through and through. But I’m willing to give bash a shot:-
$ time split input.json -l 1000000 -d -a 3Damn that was quick! Prepending the time command allows
us to see how long the entire thing took:-
real 0m14.923s
user 0m5.343s
sys 0m8.828sI’m not an expert with the *nix tools so I’ll defer to this post on StackOverflow as to what this breakdown means.
Just out of curiosity how long did Powershell take to dump out a million lines?
Measure-Command {Get-Content .\input.json | Select -First 1000000 | Out-File "input_test.json" -Encoding utf8}That took 25 seconds, whereas split took 15 seconds to
process the entire file, dump out 191 files with a million rows each and
in the correct encoding!
Lest we make Powershell jealous, we can now loop over our newly split
files (x000 to x191) and issue the
COPY command on each file. We have a two
Measure-Command’s; one for the entire thing and one for the
per file:-
Get-ChildItem . x* |
ForEach-Object {
$name = $_.FullName
"Starting: " + $name
$commandArgs = @(
"--username=`"postgres`""
"--command=`"COPY tblfun (json_blob) FROM '$name';`""
)
$duration = Measure-Command { psql.exe $commandArgs } | Select-Object 'TotalSeconds'
"Finished: " + $name + " in " + $duration.TotalSeconds + " seconds"
}You may see some errors, this is down to some of the lines in the JSON files not being valid, so that entire file gets rejected. All in all it takes around ~11 minutes to load in all the files:-
Minutes : 10
Seconds : 59
Milliseconds : 405
Ticks : 6594056956
TotalDays : 0.00763201036574074
TotalHours : 0.183168248777778
TotalMinutes : 10.9900949266667
TotalSeconds : 659.4056956
TotalMilliseconds : 659405.6956Okay that isn’t too bad. It’s time to parallelize the work.
Again, I’m hampered by the version of Powershell I’m on, newer
versions of Powershell support the -Parallel flag on
the ForEach-Object command. Luckily, we can work around it
as the regular foreach does support the
-parallel flag, the restriction being that we have to do so
inside of a workflow (which ironically is now consider deprecated):-
workflow loadItAll {
$array = Get-ChildItem . x* | Select-Object -Expand FullName
foreach -parallel -throttlelimit 2 ($item in $array) {
$name = $item
"Starting: " + $name
$commandArgs = @(
"--username=`"postgres`""
"--command=`"COPY tblfun (json_blob) FROM '$name';`""
)
$duration = Measure-Command { psql.exe $commandArgs } | Select-Object 'TotalSeconds'
"Finished: " + $name + " in " + $duration.TotalSeconds + " seconds"
}
}
$total = Measure-Command {
loadItAll | Out-Default
}
"All Finished in " + $total.TotalSeconds + " seconds" I’m starting with a throttle limit of two, and then slowly working my way up. Remember to truncate the table before each execution of the above script.
| Throttle Limit | Duration (secs) |
|---|---|
| 2 | 388 |
| 4 | 252 |
| 6 | 239 |
Hmmm, something is awry here. You’ll notice the output for some of
the files took as long as 8 seconds, instead of the 4 seconds we saw
earlier. Poking around the PG documentation, we see that PG supports
UNLOGGED tables:-
If specified, the table is created as an unlogged table. Data written to unlogged tables is not written to the write-ahead log (see Chapter 29), which makes them considerably faster than ordinary tables. However, they are not crash-safe: an unlogged table is automatically truncated after a crash or unclean shutdown. The contents of an unlogged table are also not replicated to standby servers. Any indexes created on an unlogged table are automatically unlogged as well.
We can change our current table to an UNLOGGED table by
running this command:-
ALTER TABLE public.tblfun SET UNLOGGED;Okay, let’s try the above again this time with an
UNLOGGED table:-
| Throttle Limit | Duration (secs) | Unlogged |
|---|---|---|
| 2 | 388 | No |
| 2 | 299 | Yes |
| 4 | 252 | No |
| 4 | 197 | Yes |
| 6 | 239 | No |
| 6 | 191 | Yes |
So UNLOGGED tables are clearly faster, but probably not
suitable for important data. Let’s continue to poke around the
documentation and see what else we can turn off that might effect bulk
inserts. We know from earlier that PG has a carries out routine
vacuuming, this is controlled by the autovacuum_enabled
flag:-
Enables or disables the autovacuum daemon for a particular table. If true, the autovacuum daemon will perform automatic VACUUM and/or ANALYZE operations on this table following the rules discussed in Section 23.1.6. If false, this table will not be autovacuumed, except to prevent transaction ID wraparound. See Section 23.1.5 for more about wraparound prevention. Note that the autovacuum daemon does not run at all (except to prevent transaction ID wraparound) if the autovacuum parameter is false; setting individual tables’ storage parameters does not override that. Therefore there is seldom much point in explicitly setting this storage parameter to true, only to false.
I’m not brave enough to disable routine vacuuming for the entire database, so let’s just disable it for the table we are inserting into:-
ALTER TABLE public.tblfun SET (autovacuum_enabled = FALSE);Let’s do the same run:-
| Throttle Limit | Duration (secs) | Unlogged | Autovacuum Enabled |
|---|---|---|---|
| 2 | 388 | No | Yes |
| 2 | 299 | Yes | Yes |
| 2 | 306 | Yes | No |
| 4 | 252 | No | Yes |
| 4 | 197 | Yes | Yes |
| 4 | 197 | Yes | No |
| 6 | 239 | No | Yes |
| 6 | 191 | Yes | Yes |
| 6 | 193 | Yes | No |
It doesn’t look like disabling routine vacuuming had any real effect.
Perhaps UNLOGGED tables are excluded by their nature. The
other thing we can try is to upgrade PG from 9.5 to latest version.
A brand spanking new install of PG 12 with default settings is now
installed and ready to go. Let’s pick up from where we left off. I’m
excluding the results for the autovacuum, as they had little or no
effect, and only including the results for UNLOGGED
table.
| Throttle Limit | Duration (secs) | PG Version |
|---|---|---|
| 2 | 299 | 9.5 |
| 2 | 194 | 12.3 |
| 4 | 197 | 9.5 |
| 4 | 129 | 12.3 |
| 6 | 191 | 9.5 |
| 6 | 112 | 12.3 |
| 8 | 107 | 12.3 |
| 10 | 106 | 12.3 |
| 12 | 110 | 12.3 |
It looks like we’ve hit a the ceiling at 6+ parallel copies running; upgrading to PG 12.3 really paid off taking us just under two minutes to insert our 20GB JSON file. Not bad!
Tweet![]()