{kind=link}
Reducing memory consumption and time taken by 80%
In my previous
article, we covered how we found and solved a fixed cost of using
PutObject on the AWS S3 .NET client; it was also mentioned
that we transform the image before it is uploaded to AWS S3 - this is a
process that is executed at least 400,000 times a day. With that in mind
I decided it was worth exploring the entire code path. As always you can
find all the code talked about here,
and we will be using this
image in our testing. Let us take a look at the existing
implementation. Before we can transform an image we need to get a hold
of it:-
private static byte[] GetImageFromUrl(string url)
{
byte[] data;
var request = (HttpWebRequest)WebRequest.Create(url);
request.Timeout = 10000;
request.ReadWriteTimeout = 10000;
using (var response = request.GetResponse())
using (var responseStream = response.GetResponseStream())
using (var memoryStream = new MemoryStream())
{
int count;
do
{
var buf = new byte[1024];
count = responseStream.Read(buf, 0, 1024);
memoryStream.Write(buf, 0, count);
} while (responseStream.CanRead && count > 0);
data = memoryStream.ToArray();
}
return data;
}Do you see that .ToArray()? It is evil. I do
not have the statistics to hand but I know for a fact I have seen images
larger than four megabytes come through this code path. That does not
bode well - a quick peak at the
implementation shows us why:-
public virtual byte[] ToArray()
{
BCLDebug.Perf(_exposable, "MemoryStream::GetBuffer will let you avoid a copy.");
byte[] copy = new byte[_length - _origin];
Buffer.InternalBlockCopy(_buffer, _origin, copy, 0, _length - _origin);
return copy;
}The LOH threshold is 85,000 bytes this would mean any
images larger than the threshold would go straight onto the LOH - this
is a problem, I covered why it is a problem in my previous
article. At this point curiosity got the better of me, I really
wanted to know the size of images coming into this service.
The service processes hundreds of thousands images per day, all I need is a quick sample and idea of the size and shape of incoming data. We have a job that runs at 14:00 every day to pull the latest images from one of our customers.
Hitting their service manually returns 14,630 images to
be processed. Spinning up a quick console app to perform a
HEAD request and get the Content-Length
header:-
Total Images: 14,630
Images Above LOH Threshold: 14,276
Average Image Size: 253,818 bytes
Largest Image Size: 693,842 bytes
Smallest Image Size: 10,370 bytes
Standard Deviation of Sizes: 101,184Yikes, that is a huge standard deviation and 97.58% of the
images are above the LOH threshold (85,000 bytes). Now that
we know the spread of image sizes, we can resume looking at the rest of
the current implementation:-
public void Transform(string url)
{
var bytes = GetImageFromUrl(url);
if (CanCreateImageFrom(bytes))
{
using (var stream = new MemoryStream(bytes))
using (var originalImage = Image.FromStream(stream))
using (var scaledImage = ImageHelper.Scale(originalImage, 320, 240))
using (var graphics = Graphics.FromImage(scaledImage))
{
ImageHelper.TransformImage(graphics, scaledImage, originalImage);
// upload scaledImage to AWS S3 in production, in the test harness write to disk
using (var fileStream = File.Create(@"..\..\v1.jpg"))
{
scaledImage.Save(fileStream, ImageFormat.Jpeg);
}
}
}
}
private static bool CanCreateImageFrom(byte[] bytes)
{
try
{
using (var stream = new MemoryStream(bytes))
{
Image.FromStream(stream);
}
}
catch (ArgumentException)
{
return false;
}
return true;
}I have suspicions about the two MemoryStream’s knocking
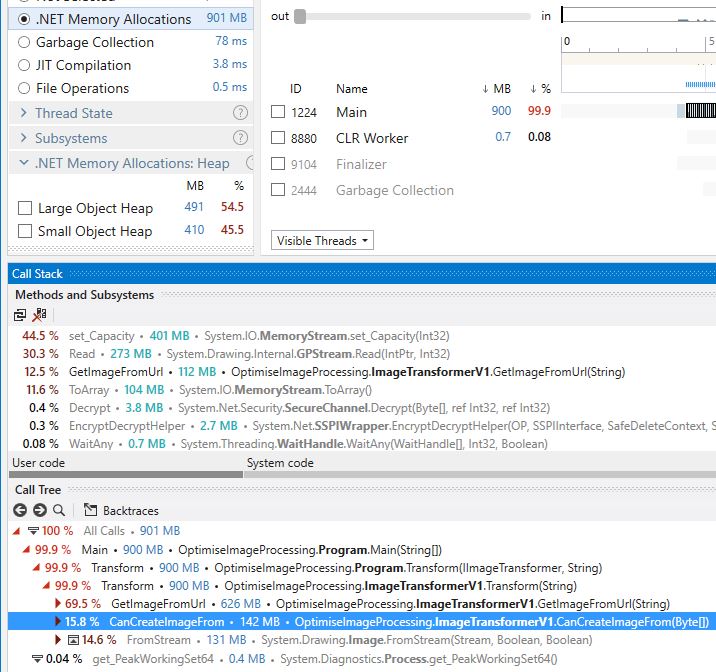
about but dotTrace can confirm or deny my suspicions. Running
V1 with the sample image one hundred times:-
| V1 | |
|---|---|
| Took (ms) | 10,297 |
| Allocated (kb) | 851,894 |
| Peak Working Set (kb) | 96,276 |
| Gen 0 collections | 184 |
| Gen 1 collections | 101 |
| Gen 2 collections | 101 |
| - | |
| dotTrace Total RAM (MB) | 901 |
| dotTrace SOH (MB) | 410 |
| dotTrace LOH (MB) | 491 |
Using dotTrace we can see where the biggest costs are:-
Now that we have established a baseline - lets get cracking!
If we inline the GetImageFromUrl and remove the
CanCreateImageFrom - which is not needed because we check
the Content-Type earlier in the code path, we can directly
operate on the incoming stream.
public class ImageTransformerV2 : IImageTransformer
{
public void Transform(string url)
{
var request = WebRequest.CreateHttp(url);
request.Timeout = 10000;
request.ReadWriteTimeout = 10000;
using (var response = request.GetResponse())
using (var responseStream = response.GetResponseStream())
using (var originalImage = Image.FromStream(responseStream))
using (var scaledImage = ImageHelper.Scale(originalImage, 320, 240))
using (var graphics = Graphics.FromImage(scaledImage))
{
ImageHelper.TransformImage(graphics, scaledImage, originalImage);
// upload scaledImage to AWS S3 in production, in the test harness write to disk
using (var fileStream = File.Create(@"..\..\v2.jpg"))
{
scaledImage.Save(fileStream, ImageFormat.Jpeg);
}
}
}
}Stats for V2:-
| V1 | V2 | % | |
|---|---|---|---|
| Took (ms) | 10,297 | 7,844 | -23.82% |
| Allocated (kb) | 851,894 | 527,246 | -38.10% |
| Peak Working Set (kb) | 96,276 | 69,436 | -27.87% |
| Gen 0 collections | 184 | 100 | -45.65% |
| Gen 1 collections | 101 | 100 | -00.99% |
| Gen 2 collections | 101 | 100 | -00.99% |
| - | |||
| dotTrace Total RAM (MB) | 901 | 550 | -38.95% |
| dotTrace SOH (MB) | 410 | 162 | -60.48% |
| dotTrace LOH (MB) | 491 | 388 | -20.97% |
Awesome, a few minor tweaks and all the metrics have dropped across the board.
Using dotTrace again, we can see the next biggest cost:-
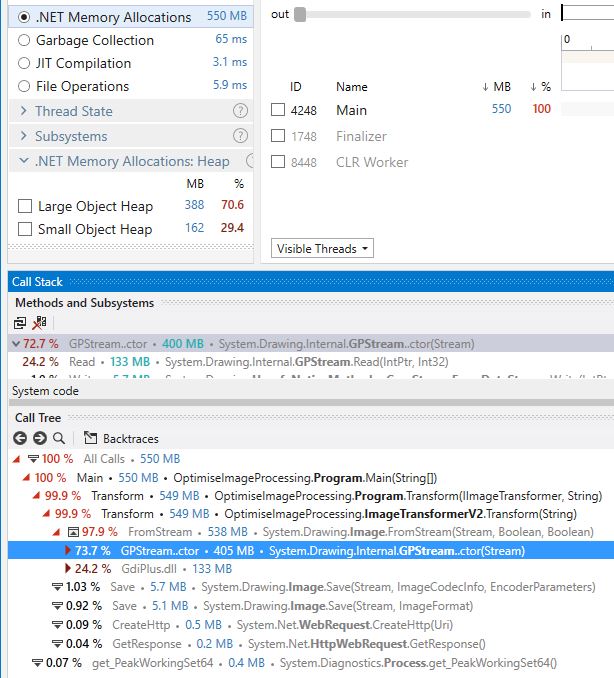
Something is happening inside of the constructor of
GPStream that is costing us dearly. Luckily dotTrace can
show us the decompiled source which saves us a trip to Reference
Sources:-
internal GPStream(Stream stream)
{
if (!stream.CanSeek)
{
byte[] buffer = new byte[256];
int offset = 0;
int num;
do
{
if (buffer.Length < offset + 256)
{
byte[] numArray = new byte[buffer.Length * 2];
Array.Copy((Array) buffer, (Array) numArray, buffer.Length);
buffer = numArray;
}
num = stream.Read(buffer, offset, 256);
offset += num;
} while (num != 0);
this.dataStream = (Stream) new MemoryStream(buffer);
}
else
this.dataStream = stream;
}You know when you ask yourself a question out loud and you can answer
it straight away? The question was “What?! I can’t seek on the incoming
HTTP stream?”. No, you can’t. Makes total sense when you think about it
and because the incoming Stream is not seekable
GPStream has to take a copy of it.
Okay, first thing - can we move the cost from framework code to our code? It is not pretty but something like this works:-
public void Transform(string url)
{
var request = WebRequest.CreateHttp(url);
request.Timeout = 10000;
request.ReadWriteTimeout = 10000;
var memoryStream = new MemoryStream();
using (var response = request.GetResponse())
using (var responseStream = response.GetResponseStream())
{
responseStream.CopyTo(memoryStream);
}
using (var originalImage = Image.FromStream(memoryStream))
using (var scaledImage = ImageHelper.Scale(originalImage, 320, 240))
using (var graphics = Graphics.FromImage(scaledImage))
{
ImageHelper.TransformImage(graphics, scaledImage, originalImage);
// upload scaledImage to AWS S3 in production, in the test harness write to disk
using (var fileStream = File.Create(@"..\..\v2.jpg"))
{
scaledImage.Save(fileStream, ImageFormat.Jpeg);
}
}
}dotTrace shows us that we have indeed moved the cost from framework code into our code:-
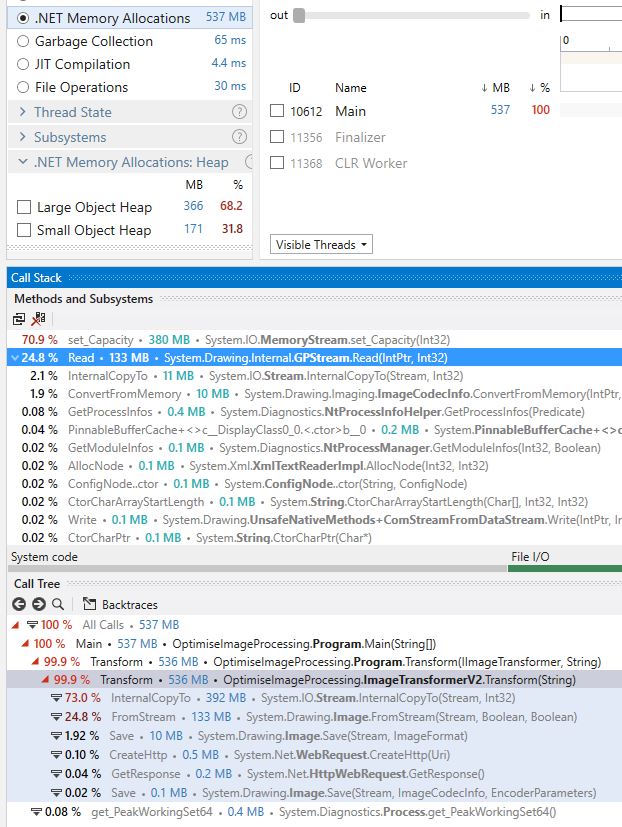
Now we could use our old friend System.Buffers
and just rent a byte[] then pass that to the constructor of
the MemoryStream. That would work, except two things.
Firstly, Content-Length is not
guaranteed to be set. Secondly, a few weeks earlier I was poking
around the .NET
driver for Cassandra when I came across
Microsoft.IO.RecyclableMemoryStream and it felt like it was
exactly what I needed here. If you want to learn more about
RecyclableMemoryStream Ben Watson has a great
post on what it is and its various use cases. Jumping straight into
V3:-
public class ImageTransformerV3 : IImageTransformer
{
private readonly RecyclableMemoryStreamManager _streamManager;
public ImageTransformerV3()
{
_streamManager = new RecyclableMemoryStreamManager();
}
public void Transform(string url)
{
var request = WebRequest.CreateHttp(url);
request.Timeout = 10000;
request.ReadWriteTimeout = 10000;
request.AllowReadStreamBuffering = false;
request.AllowWriteStreamBuffering = false;
MemoryStream borrowedStream;
using (var response = request.GetResponse())
{
if (response.ContentLength == -1) // Means that content length is NOT sent back by the third party server
{
borrowedStream = _streamManager.GetStream(url); // then we let the stream manager had this
}
else
{
borrowedStream = _streamManager.GetStream(url, (int)response.ContentLength); // otherwise we borrow a stream with the exact size
}
int bufferSize;
if (response.ContentLength == -1 || response.ContentLength > 81920)
{
bufferSize = 81920;
}
else
{
bufferSize = (int) response.ContentLength;
}
// close the http response stream asap, we only need the contents, we don't need to keep it open
using (var responseStream = response.GetResponseStream())
{
responseStream.CopyTo(borrowedStream, bufferSize);
}
}
using (borrowedStream)
using (var originalImage = Image.FromStream(borrowedStream))
using (var scaledImage = ImageHelper.Scale(originalImage, 320, 240))
using (var graphics = Graphics.FromImage(scaledImage))
{
ImageHelper.TransformImage(graphics, scaledImage, originalImage);
// upload scaledImage to AWS S3 in production, in the test harness write to disk
using (var fileStream = File.Create(@"..\..\v3.jpg"))
{
scaledImage.Save(fileStream, ImageFormat.Jpeg);
}
}
}
}One of my favourite things about RecyclableMemoryStream
is that it is a drop-in replacement for MemoryStream. The
ArrayPool from System.Buffers requires you to
Rent and then Return. Whereas
RecyclableMemoryStream handles everything for you as it
implements IDisposable. Anyway, enough of my admiration for
RecyclableMemoryStream; stats for V3:-
| V1 | V2 | V3 | % (V3 vs. V1) | |
|---|---|---|---|---|
| Took (ms) | 10,297 | 7,844 | 7,688 | -25.33% |
| Allocated (kb) | 851,894 | 527,246 | 125,739 | -85.24% |
| Peak Working Set (kb) | 96,276 | 69,436 | 71,140 | -26.10% |
| Gen 0 collections | 184 | 100 | 29 | -84.23% |
| Gen 1 collections | 101 | 100 | 2 | -98.01% |
| Gen 2 collections | 101 | 100 | 1 | -99.00% |
| - | ||||
| dotTrace Total RAM (MB) | 901 | 550 | 152 | -83.12% |
| dotTrace SOH (MB) | 410 | 162 | 150 | -63.41% |
| dotTrace LOH (MB) | 491 | 388 | 1.6 | -99.67% |
That is an incredible improvement from V1. This
is what V3 looks like in dotTrace:-
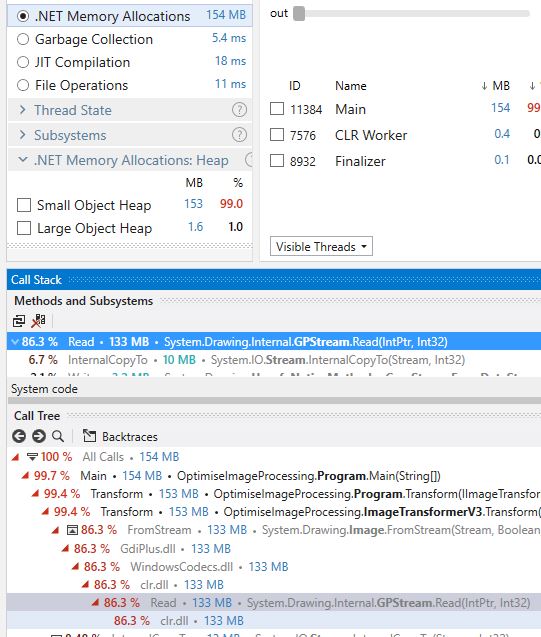
My knowledge on System.Drawing is pretty sketchy but an
afternoon reading about it leads me to the conclusion that if you can
avoid using System.Drawing then you are better off. Whilst
searching for an alternative to System.Drawing, I came
across this
article written by Omar Shahine. Huh, I never considered the
overloads. Takes two seconds to try this so we might as well; v3 with
useEmbeddedColorManagement disabled and
validateImageData turned off these are the stats:-
| V1 | V2 | V3 | % (V3 vs. V1) | |
|---|---|---|---|---|
| Took (ms) | 10,297 | 7,844 | 7,563 | -26.55% |
| Allocated (kb) | 851,894 | 527,246 | 128,166 | -84.95% |
| Peak Working Set (kb) | 96,276 | 69,436 | 53,688 | -44.23% |
| Gen 0 collections | 184 | 100 | 30 | -83.69% |
| Gen 1 collections | 101 | 100 | 2 | -98.01% |
| Gen 2 collections | 101 | 100 | 1 | -99.00% |
| - | ||||
| dotTrace Total RAM (MB) | 901 | 550 | 154 | -82.90% |
| dotTrace SOH (MB) | 410 | 162 | 153 | -62.68% |
| dotTrace LOH (MB) | 491 | 388 | 1.6 | -99.67% |
A minor increase in some areas but a noticeable drop in
Peak Working Set - great! A slightly more recent
article by Bertrand Le Roy goes through the various alternatives to
System.Drawing. Thankfully, there is a nice little chart at
the bottom that shows performance in the context of time taken.
According to that article PhotoSauce.MagicScaler
is pretty magic - word of warning this library is Windows only. I wonder
how magic it really is? Spinning V4 up:-
public class ImageTransformerV4 : IImageTransformer
{
public void Transform(string url)
{
// truncated for brevity
MagicImageProcessor.EnableSimd = false;
MagicImageProcessor.EnablePlanarPipeline = true;
using (borrowedStream)
{
// upload scaledImage to AWS S3 in production, in the test harness write to disk
using (var fileStream = File.Create(@"..\..\v4.jpg"))
{
MagicImageProcessor.ProcessImage(borrowedStream, fileStream, new ProcessImageSettings()
{
Width = 320,
Height = 240,
ResizeMode = CropScaleMode.Max,
SaveFormat = FileFormat.Jpeg,
JpegQuality = 70,
HybridMode = HybridScaleMode.Turbo
});
}
}
}
}And the stats:-
| V1 | V2 | V3 | V4 | % (V4 vs. V1) | |
|---|---|---|---|---|---|
| Took (ms) | 10,297 | 7,844 | 7,563 | 1,672 | -83.76% |
| Allocated (kb) | 851,894 | 527,246 | 128,166 | 135,876 | -84.05% |
| Peak Working Set (kb) | 96,276 | 69,436 | 53,688 | 35,596 | -63.02% |
| Gen 0 collections | 184 | 100 | 30 | 32 | -82.60% |
| Gen 1 collections | 101 | 100 | 2 | 2 | -98.01% |
| Gen 2 collections | 101 | 100 | 1 | 1 | -99.00% |
| - | |||||
| dotTrace Total RAM (MB) | 901 | 550 | 154 | 165 | -81.68% |
| dotTrace SOH (MB) | 410 | 162 | 153 | 162 | -60.48% |
| dotTrace LOH (MB) | 491 | 388 | 1.6 | 1.6 | -99.67% |
An insane drop in time taken and a healthy drop in
Peak Working Set!
That is magic.
Pun not intended - just before this article was about to be published I saw this interesting tweet:-
Awwwwww Yeaaaaaaah 😎 https://t.co/E4wzeQA3MC
— JimBobSquarePants (@James_M_South) June 29, 2018
Naturally I was interested, spinning up V5 gave me
similar results to V4 except a noticeable increase in time
taken, peak working set, and LOH allocations. After a conversation on
their Gitter
I learnt that they are:-
If your image transformation process is mostly resizing and you are
hosted on Windows then look into using
PhotoSauce.MagicScaler with
Microsoft.IO.RecyclableMemoryStream you will see a sixty to
ninety nine percent reduction in various performance related
metrics!
![]()